TL;DR
Prisma 使用 cursor, 包一个 Readable stream, 再通过 Transform 格式化数据最后 pipe 到 response 即可.
整合 Query + Readable stream
-
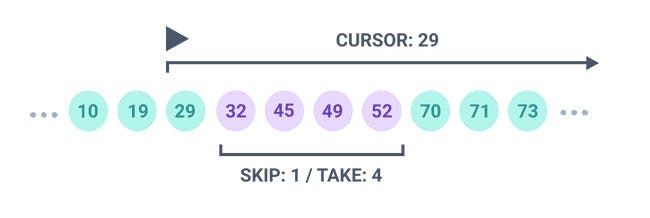
平时查找分页数据基本都是使用 limit + offset, 优点是可以跳到任何一页. 当然缺点也是明显的, 例如从 offset 1e4 开始拿, 前 1e4 条记录也是要走一遍的.
-
在不需要跳页的情况下, cursor 模式显得更加适合. 但需要一个唯一且顺序的字段充当 cursor 这一角色, 例如 id (id > cursor 查询).
So, 直接用代码说话.
// 首先定义一个fetcher, 用于取数据库数据
const fetcher = (cursor?: number) => {
// schema 请指定 id 为主键
return this.prisma.model.findMany({
take: 1000,
skip: cursor ? 1 : 0,
cursor: cursor ? { id: cursor } : undefined,
})
}然后, 我们将数据源转为 Readable stream
const streamQuery = <T extends { id: number }>(
fetcher: (cursor?: number) => Promise<T[]>,
) => {
let cursor = undefined
return new Readable({
// stream 默认只接受 string/Buffer (或 Uint8Array), 如需使用其它类型, 请指定为 true
// 当然上述的, 除了 null. 作为特殊用途, 这用于结束 stream
objectMode: true,
// read() 被设计为同步/异步均可, 所以可以安心与信赖地使用 async/await
async read() {
try {
const items = await fetcher(cursor)
if (items.length === 0) {
this.push(null)
} else {
for (const item of items) {
this.push(item)
}
cursor = items[items.length - 1].id
}
} catch (e) {
this.destroy(e)
}
},
})
}
// 使用
const queryStream = streamQuery(fetcher)格式化并输出到 Excel
因为已经转换为 stream, 格式化就简单了, 直接使用 Transform 处理数据即可
const formatter = new Transform({
objectMode: true,
transform(chunk, _, callback) {
// 处理你的数据, 使用并推入 stream
callback(null, [chunk.a, chunk.b, chunk.c])
},
})
queryStream.pipe(formatter)处理后的数据, 使用 Writable 接收, commit 到 excel 的 stream 中
import Excel from 'exceljs'
const exportToXlsxStream = (header: string[]) => {
// 使用 PassThrough 将 Writable 转到 Readable, 后续可以灵活地最后处理数据
const reader = new PassThrough()
// 创建 workbook
const workbook = new Excel.stream.xlsx.WorkbookWriter({
// 这当然可以直接使用 Writable, 如 `fs.createWriteStream` 写入文件
stream: reader,
})
// 先把表头都加了
const worksheet = workbook.addWorksheet('exported')
const columns = header.map((h) => {
return {
header: h,
key: h,
}
})
worksheet.columns = columns
// 收到由 formatter 送过来的行数据后, 直接 commit 到 excel 中
const writer = new Writable({
objectMode: true,
write(chunk, _, callback) {
// 注意这个 commit
// 如无 commit, 行数据将一直在内存中而非 push 入 stream
worksheet.addRow(chunk).commit()
callback()
},
})
// 当 formatter 过来的所有数据处理完成, 把 excel 最后的格式数据写入即可
writer.on('finish', async () => {
worksheet.commit()
await workbook.commit()
})
return { reader, writer }
}流程最后就是, 这样!
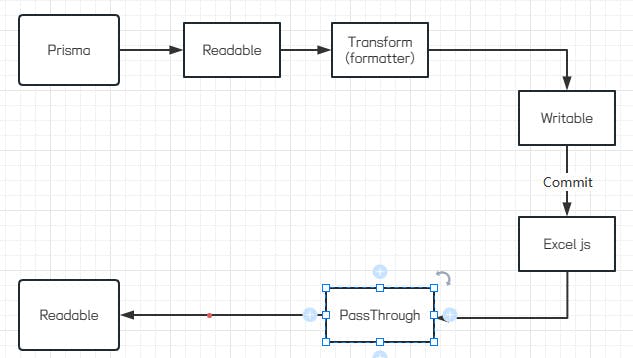
const exporter = exportToXlsxStream(['A', 'B', 'C'])
queryStream.pipe(formatter).pipe(exporter.writer)
// 之后 exporter.reader 就可以随便用辣
// 1. 如果你在使用nestjs, new StreamableFile(exporter.reader)
// 2. 如果突然变了需求写文件, exporter.reader.pipe(fs.createWriteStream('文件名')) 也可以.前端
作为一个前端博客, 当然要有点前端东西啦.
axios
.post(
apiUrl,
{ ...params },
{
responseType: 'blob',
onDownloadProgress(e) {
// 这里就是下载进度啦
},
},
)
.then((res) => {
if (!res.data.error) {
const href = URL.createObjectURL(res.data)
const anchor = document.createElement('a')
anchor.href = href
anchor.download = 'export.xlsx'
document.body.appendChild(anchor)
anchor.click()
document.body.removeChild(anchor)
URL.revokeObjectURL(href)
} else {
console.error(res.data.error)
}
})
// 确实只有一点小彩蛋
通过瞄一眼 Readable 源码就可以发现, read() 并没有 await, 为什么它可以直接使用 async/await 呢?
// https://github.com/nodejs/node/blob/main/lib/internal/streams/readable.js#L496
this._read(state.highWaterMark)原因其实很简单, Readable 拥有自身的 ReadableState (含当前数据量, 状态, 模式等). 既然 read() 读不到, 只需要将 state.reading 设置为 true 后就不管啦~
// 瞄两眼 https://github.com/nodejs/node/blob/main/lib/internal/streams/readable.js#L479
if (
state.ended ||
state.reading ||
state.destroyed ||
state.errored ||
!state.constructed
) {
doRead = false
debug('reading, ended or constructing', doRead)
} else if (doRead) {
// ...
state.reading = true // 诶嘿
// ...
// Call internal read method
try {
this._read(state.highWaterMark)
} catch (err) {
errorOrDestroy(this, err)
}
}
// ...
// 随后会根据用户调用 push() -> addChunk() 后 maybeReadMore() 继续走上面流程即可
// https://github.com/nodejs/node/blob/main/lib/internal/streams/readable.js#L233相关库
-- Fin --